En breve
- Google anunció que su algoritmo TurboQuant puede reducir un importante cuello de botella en la memoria de inteligencia artificial por al menos seis veces sin pérdida de precisión durante la inferencia.
- Las acciones de empresas de memoria, como Micron, Western Digital y Seagate, bajaron tras la difusión del estudio.
- El método comprime la memoria de inferencia, no los pesos del modelo, y solo ha sido probado en bancas de investigación.
Google Research publicó el miércoles sobre TurboQuant, un algoritmo de compresión que reduce significativamente un cuello de botella en la memoria de inferencia por al menos seis veces, manteniendo una precisión nula en la pérdida.
El artículo se presentará en ICLR 2026 y la reacción en línea fue rápida.
El CEO de Cloudflare, Matthew Prince, lo describió como el momento DeepSeek de Google. Las acciones de empresas de memoria, como Micron, Western Digital y Seagate, sufrieron caídas el mismo día.
¿Es real?
La eficiencia de la cuantización es un gran logro por sí sola. Sin embargo, «cero pérdida de precisión» necesita un contexto.
TurboQuant se enfoca en la caché KV, la parte de la memoria GPU que almacena todo lo que un modelo de lenguaje necesita recordar durante una conversación.
A medida que las ventanas de contexto crecen hacia millones de tokens, esas cachés se expanden a cientos de gigabytes por sesión. Ese es el verdadero cuello de botella; no la potencia de cálculo, sino la memoria cruda.
Los métodos de compresión tradicionales intentan reducir esas cachés redondeando números a la baja, desde flotantes de 32 bits a números enteros de 16, 8 y 4 bits. Para entenderlo mejor, imagina reducir una imagen de 4K a Full HD o 720p. Es fácil reconocer que es la misma imagen, pero hay más detalles en resolución 4K.
El inconveniente es que deben almacenar «constantes de cuantización» adicionales junto con los datos comprimidos para evitar que el modelo pierda su efectividad. Esas constantes suman entre 1 y 2 bits por valor, erosionando parcialmente las ganancias.
TurboQuant afirma eliminar por completo esa sobrecarga.
Esto se logra mediante dos sub-algoritmos. PolarQuant separa la magnitud de la dirección en los vectores, y QJL (Quantized Johnson-Lindenstrauss) toma el pequeño error residual y lo reduce a un solo bit de signo, positivo o negativo, sin constantes almacenadas.
El resultado, según Google, es un estimador matemáticamente imparcial para los cálculos de atención que impulsan los modelos transformadores.
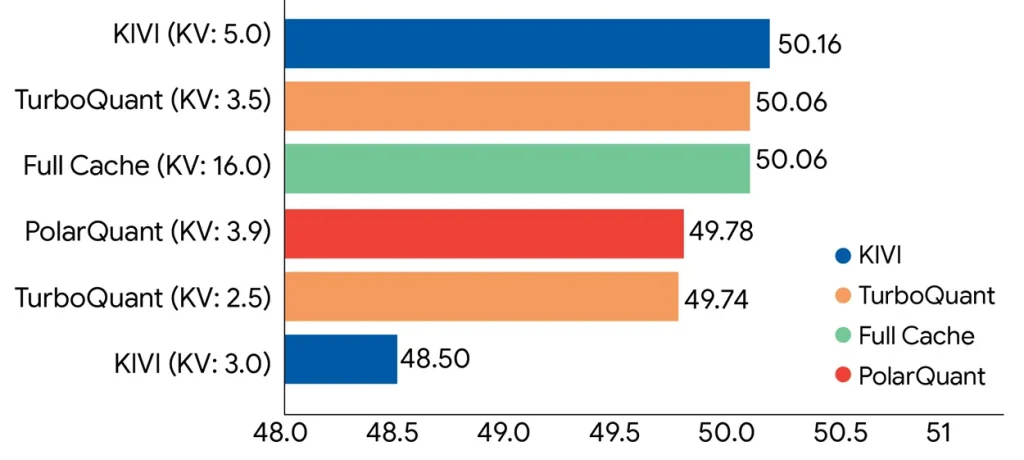
En las pruebas realizadas con Gemma y Mistral, TurboQuant igualó el rendimiento de precisión completa bajo una compresión de 4x, incluidos tareas de recuperación perfectas en desafíos de «aguja en un pajar» de hasta 104,000 tokens.
Para entender la relevancia de esos benchmarks, ampliar el contexto utilizable de un modelo sin perder calidad ha sido uno de los problemas más difíciles en la implementación de LLM.
Ahora, los detalles importantes.
La «cero pérdida de precisión» se aplica a la compresión de caché KV durante la inferencia, no a los pesos del modelo. La compresión de pesos es un problema completamente diferente y más complicado. TurboQuant no toca esos.
Lo que comprime es la memoria temporal que almacena los cálculos de atención intermedios, lo cual es más perdonable, ya que esos datos teóricamente pueden ser reconstruidos.
Además, existe la brecha entre un benchmark limpio y un sistema de producción que atiende miles de millones de solicitudes. TurboQuant fue probado en modelos de código abierto—Gemma, Mistral, Llama—y no en el propio stack Gemini de Google a gran escala.
A diferencia de los ganancias de eficiencia de DeepSeek, que requirieron decisiones arquitectónicas profundas desde el inicio, TurboQuant no requiere reentrenamiento ni ajuste y afirma tener sobrecostos de tiempo de ejecución mínimos. En teoría, se integra directamente en los pipelines de inferencia existentes.
Ese es el factor que asustó al sector de hardware de memoria porque, si funciona en producción, cada laboratorio de IA importante operará de manera más eficiente con las mismas GPU que ya poseen.
El artículo se presentará en ICLR 2026. Hasta que se produzca en un entorno real, el titular de «cero pérdida» permanecerá en el laboratorio.
Informe diario Newsletter
Comienza cada día con las principales noticias del momento, además de reportajes originales, un pódcast, videos y más.
Fuente: decrypt.co