Resumen
- Microsoft ha lanzado dos modalidades diferentes que combinan GPT y Claude para mejorar la calidad de la investigación por IA.
- Critique permite que los modelos colaboren, mientras que Council los hace trabajar en paralelo, con un tercer modelo que identifica las discrepancias.
- Este flujo de trabajo con dos modelos corrige las alucinaciones, citas débiles y otros problemas asociados a la investigación en IA de un solo modelo.
La investigación avanzada en IA ha sido uno de los temas más candentes en la tecnología este año. Google anunció su agente de investigación para Gemini en diciembre de 2024, OpenAI presentó su propio agente de investigación en febrero de 2025, xAI hizo lo mismo, Perplexity intensificó su enfoque, y Claude de Anthropic se ganó una fiel audiencia entre profesionales que necesitan respuestas detalladas y con citas, introduciendo su agente en abril del año pasado.
Cada empresa ha intentado demostrar que su único modelo de IA es el investigador más inteligente. Microsoft, sin embargo, ha planteado la pregunta: ¿por qué elegir solo uno?
La compañía anunció dos nuevas características para la herramienta Researcher de Copilot—denominadas Critique y Council—que hacen que GPT de OpenAI y Claude de Anthropic trabajen juntos en la misma tarea de investigación de forma secuencial. Según las pruebas de Microsoft, este enfoque supera a todos los sistemas probados, incluidos los modelos de las empresas de IA más reconocidas.
Introduciendo Critique, un nuevo sistema de investigación en profundidad mult modelo en M365 Copilot.
Puedes utilizar múltiples modelos juntos para generar respuestas y reportes óptimos. pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) 30 de marzo de 2026
“Critique es un nuevo sistema de investigación profunda mult modelo diseñado para tareas de investigación complejas. Separa la generación de la evaluación y utiliza una combinación de modelos de Frontier Labs, incluidos Anthropic y OpenAI,” explica Microsoft. “Un modelo lidera la fase de generación, planificando la tarea, iterando en la búsqueda y produciendo un borrador inicial, mientras que un segundo modelo se enfoca en la revisión y refinamiento, actuando como un revisor experto antes de que se produzca el informe final.”
El problema básico que Critique está diseñado para solucionar es que cada herramienta de investigación en IA hoy en día opera de la misma manera. Haces una pregunta, un modelo planifica una búsqueda, examina fuentes, escribe un informe y te lo entrega. Ese único modelo realiza todo sin que nadie revise su trabajo.
Esto puede llevar a que se cuelen algunas alucinaciones, errores en citas y afirmaciones imprecisas, entre otros problemas.
Critique rompe ese flujo de trabajo en dos. GPT maneja la primera fase: planifica la investigación, selecciona fuentes y redacta un borrador inicial. Luego, Claude actúa como un editor riguroso, revisando el informe por su precisión factual, la calidad de las citas y si la respuesta realmente aborda lo que se preguntó. Solo después de esa revisión, el informe final llega al usuario. Microsoft menciona que los roles también pueden invertirse eventualmente, con Claude elaborando el borrador y GPT haciendo la crítica, aunque por ahora GPT va primero.
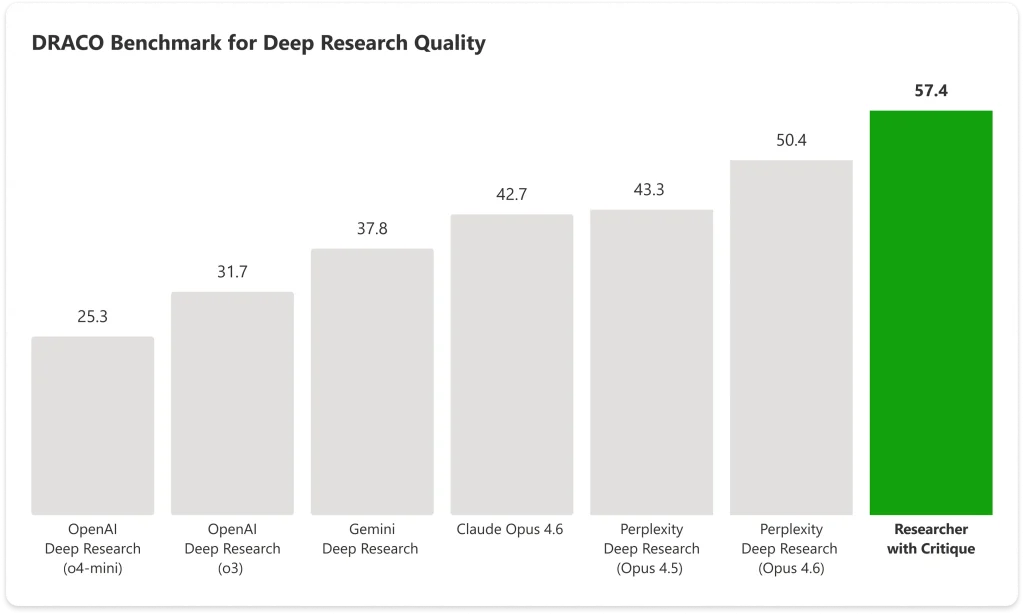
En el benchmark DRACO—una prueba estandarizada que cubre 100 tareas de investigación complejas en 10 dominios, incluidos medicina, derecho y tecnología—Copilot con Critique obtuvo una puntuación de 57.4, mientras que el Claude de Anthropic alcanzó solo 42.7. El sistema combinado de Microsoft supera el siguiente mejor resultado en casi un 14%.
Las mayores mejoras se observaron en la amplitud de análisis y la calidad de presentación, con un aumento significativo en la precisión factual.
La segunda función, Council, aborda el mismo problema de una manera diferente. En lugar de que un modelo revise el trabajo del otro, Council ejecuta GPT y Claude simultáneamente y coloca sus informes completos uno al lado del otro. Un tercer modelo, actuando como «juez», lee ambos y redacta un resumen explicando dónde coincidieron, dónde divergieron y qué ángulos únicos capturó cada uno que el otro pasó por alto. Comparar herramientas de investigación en IA ha sido una tarea que los usuarios han tenido que hacer por sí mismos hasta ahora.
En Critique, los modelos colaboran entre sí, mientras que en Council los modelos compiten entre sí.
Critique es la experiencia predeterminada en Researcher, mientras que Council requiere que selecciones «Model Council» de la lista para activar el modo lado a lado. Ambas características están actualmente disponibles para los usuarios que están inscritos en el programa Frontier de Microsoft, el canal de acceso anticipado para las capacidades más nuevas de Copilot. Se requiere una licencia de Microsoft 365 Copilot ($30/usuario/mes), y los usuarios también necesitan estar inscritos en Frontier para acceder a estas funciones.
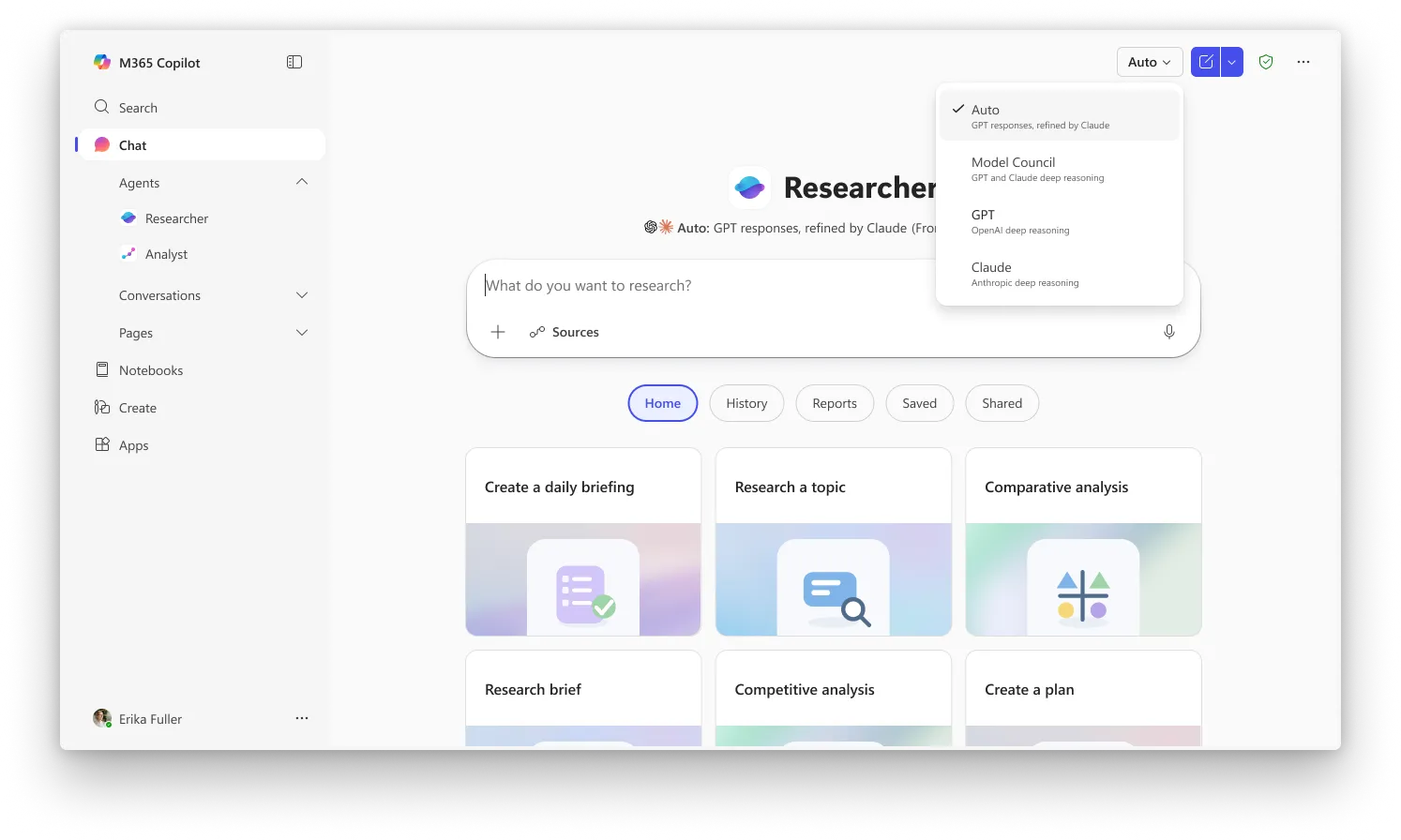
OpenAI y Microsoft tienen una asociación multimillonaria, pero la apuesta de Microsoft es que ningún modelo único permanezca en la cima por mucho tiempo, y que el verdadero valor radica en la capa de orquestación que dirige tareas a la combinación que funcione mejor.
Newsletter Daily Debrief
Comienza cada día con las principales noticias del momento, además de características originales, un podcast, videos y más.
Fuente: decrypt.co